Phase 1: Exploratory Data Analysis
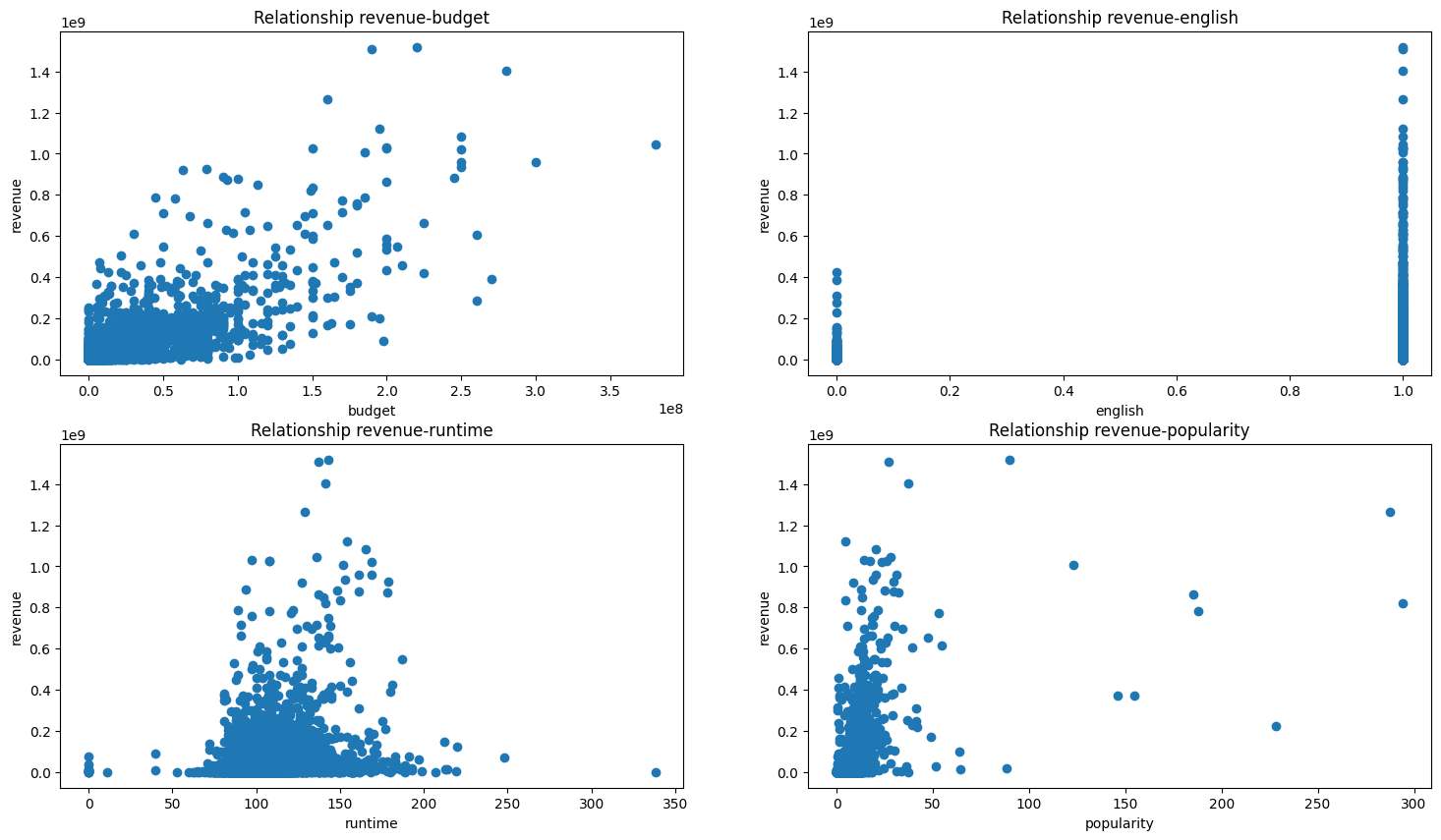
Assessed relationships between revenue and features like budget, runtime, popularity, and language.
Budget showed the highest correlation (~0.75) and was the strongest individual predictor.
Visualized insights using scatter plots and correlation matrices.
Phase 2: Feature Engineering & Regression Modeling
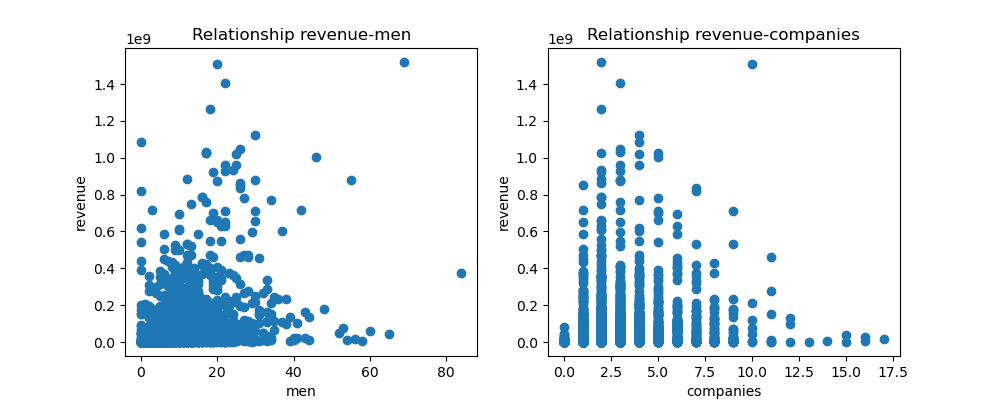
Engineered numerical features from JSON fields, such as number of male cast members and production companies. Built a multiple linear regression model using scikit-learn. Budget and popularity were the most significant predictors. The final model achieved an R² score of ~0.38 and was validated through residual analysis.
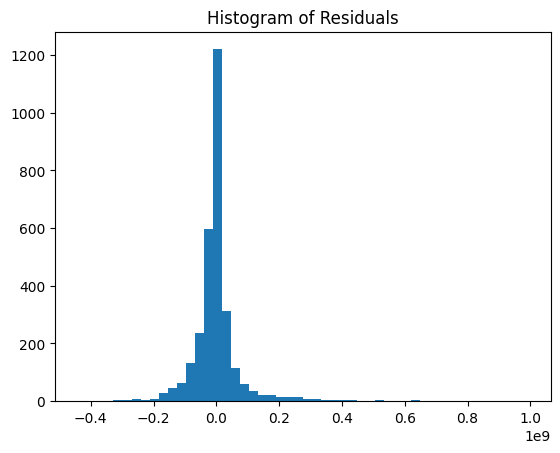
Phase 3: Model Validation & Residual Analysis
Evaluated the model’s assumptions by analyzing the distribution of residuals. A histogram revealed a roughly symmetric shape centered around zero, supporting the validity of the linear model for this dataset.